

Wen sollte das autonome Fahrzeug nun töten, den Rentner oder die Frau mit dem Kinderwagen? Man kennt das ja als Autofahrer. Ständig steht man unterwegs vor eben diesem Dilemma. Fährt man den Fußgänger um, der die Straße vor einem überquert? Weicht man doch lieber in den Gegenverkehr aus, in die Personengruppe auf dem Fußweg oder setzt man seinen Wagen gar bewusst gegen den Baum, um niemanden zu gefährden außer sich selbst? Ach so, derartige Situationen kommen eigentlich nie vor? Ein Unfall geschieht, weil man ihn nicht vorhergesehen hat? In einer solchen Situation reagiert man ohnehin instinktiv, denn Zeit zum Nachdenken bleibt nicht? Ist man aber tatsächlich noch dazu in der Lage, unterschiedliche Optionen zu prüfen, besteht auch immer eine Chance, die Kollision zu vermeiden? Durch eine abrupte Verringerung der Geschwindigkeit beispielsweise?
Häretische Fragen aus der Sicht jener, die allen Ernstes empfehlen, hochautomatische oder gar autonome Autos erst auf die Straße zu lassen, wenn man diesen einprogrammiert hat, welches Opfer sie im Ernstfall bevorzugen sollen. Eine Forderung, die nicht nur weltfremd ist, sondern auch noch prinzipielle technische Limitierungen ignoriert. Denn das, was man heute als Künstliche Intelligenz (KI) realisiert, vermag sehr wohl ein Auto zu steuern, aber ethische Prinzipien kann es dabei nicht berücksichtigen. Weil es keine Möglichkeit gibt, solche mathematisch zu formulieren.
Formale Logiken eignen sich nur zur Abbildung von Handlungen, die einer eindeutigen Bewertung nach Kriterien wie „falsch“ oder „richtig“ zugänglich sind. Wenn „Ampel rot“, dann „anhalten“ ist ein simples Beispiel. Die Berücksichtigung zahlreicher weiterer Umgebungsinformationen, darunter das dynamische Verhalten anderer Verkehrsteilnehmer, erschwert die Angelegenheit natürlich enorm. Der Begriff „Künstliche Intelligenz“ steht für eine Reihe unterschiedlicher Rechenkonzepte, mit deren Hilfe aus sehr vielen Eingangsdaten ein bezüglich einer vorgegebenen Zielstellung geeignetes Resultat kalkuliert werden kann. Fallbasierte Expertensysteme ermitteln eine Antwort aus Vergleichen mit ähnlichen Problemstellungen. Evolutionäre Algorithmen erarbeiten potentielle Lösungen über rekursive Optimierungsschritte. Und die aktuell aufgrund ihrer Flexibilität populären neuronalen Netze reduzieren komplexe Situationen auf ihre wesentlichen Parameter. Alle diese Ansätze sind so alt wie der programmierbare Digitalrechner selbst. Alle diese Ansätze sind erst jetzt praktikabel umsetzbar, da die Kapazitäten und Geschwindigkeiten elektronischer Rechner ihren Leistungsansprüchen endlich genügen und außerdem ausreichend digitale Daten vorliegen, um sie zu füttern und zu trainieren. Aber keiner dieser Ansätze beruht wirklich auf der Imitation menschlicher Lösungsstrategien.
Man betrachte dazu exemplarisch die Verlängerung der folgenden Zahlenreihe, eine Aufgabe, wie sie in Standard-Intelligenztests häufig vorkommt: 1, 8, 27, 64, 125, … Wie lautet das nächste Glied der Kette? Richtig, es ist 216. Wie sind Sie darauf gekommen? Es handelt sich offensichtlich um die Folge der Kubikzahlen 1³, 2³, 3³, 4³, 5³ mit 6³=216 als zwingender Fortsetzung. Wie würde ein Programmierer diesen Auftrag für seinen Computer übersetzen? Der Rechner ist ja nicht dazu fähig, die Konstruktionsvorschrift zu ermitteln. Er hat schlicht keine Ahnung vom Konzept „Kubikzahlen“. Er kann aber die vorgegebenen Werte als Koordinaten ansehen und durch diese ausgleichende Kurven legen. Die beste Annäherung, definiert durch die kleinstmögliche Summe der Abstände aller Datenpunkte vom Verlauf der Kurve, wird für die Prognose des gefragten Wertes eingesetzt. Da y=x³ die obige Zahlenreihe nach diesem Kriterium am besten wiedergibt, landet auch der Computer bei 216.
Sehr schnell und entlang eines Weges, den ein Mensch niemals beschreiten würde.
Ein neuronales Netz, das beispielsweise auf die Erkennung von Katzenbildern trainiert wurde, „erkennt“ Katzen so wenig wie oben skizzierte Software Kubikzahlen. Jedes artifizielle „Neuron“ stellt lediglich einen Speicherplatz für eine Ziffer dar, die mit einem veränderbaren Faktor multipliziert, also mit einer variablen Gewichtung, an andere „Neuronen“ übertragen wird. Eine typische Topologie für neuronale Netze ist der Aufbau in Schichten. Jedes Neuron einer Ebene ist dabei mit jedem Neuron der nächstfolgenden verbunden. In der ersten Schicht werden die Eingangsdaten registriert. Die letzte Schicht trägt die Ausgangswerte. Die Ebenen dazwischen addieren und multiplizieren wild herum. Legt man einer solchen Konstruktion Graustufenbilder vor, die entweder mindestens eine oder eben gar keine Katze enthalten, repräsentiert jedes Neuron der ersten Schicht ein Pixel des Fotos und übernimmt dessen Helligkeitswert. Es handelt sich also je nach Auflösung des Bildes um hunderttausende oder gar Millionen Speicherplätze, die jeweils eine Zahl zwischen „0“ (schwarz) und „1“ (weiß) beinhalten. Am Ende sollen nur noch zwei Neuronen übrig bleiben, von denen das eine „1“ anzeigt, wenn im Bild eine Katze gefunden wird und das andere entsprechend mit einer „1“ das Resultat „keine Katze“ codiert.
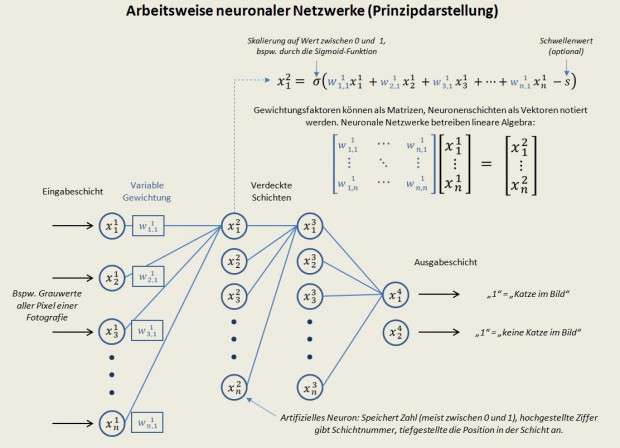

Das Netzwerk wird nun mit Zufallswerten für alle Gewichtungen initialisiert. Es erzeugt entsprechend wirre Ergebnisse für die ersten Versuche. Aber es kann sich steigern, indem es die Gewichtungsfaktoren in geeigneter Weise verändert. Dazu definiert man eine „Kostenfunktion“, die die Abweichung des kalkulierten Ergebnisses vom gewünschten Resultat wiedergibt. Ein neuronales Netz macht also im Grunde nichts weiter, als das Minimum dieser Kostenfunktion zu suchen. Wie das erläuternde Bild zeigt, handelt es sich bei einem neuronalen Netzwerk um ein Werkzeug zur Multiplikation sehr großer Matrizen und Vektoren. Eine unter dem Begriff „lineare Algebra“ bekannte mathematische Disziplin. Aus der auch die Methoden stammen, mit denen es möglich ist, jene Gewichtungsfaktoren zu finden, deren Veränderung den größten Effekt auf die Kostenfunktion ausübt. So wird nach und nach das neuronale Netz immer besser darin, Katzenbilder korrekt als solche zu identifizieren. Aber hat es dabei wirklich gelernt, wie eine Katze aussieht? Findet sich das Bild einer Katze in den Gewichtungsfaktoren wieder? Man könnte ja vermuten, in den verdeckten Schichten würden zunächst Bildkanten identifiziert, aus diesen einfache Formen (Kreise, Rechtecke) abgeleitet, um schließlich zu den groben geometrischen Konturen einer Katze zu gelangen. Der detaillierte Blick in real existierende, gut trainierte Netzwerke aber zeigt nichts dergleichen. Sondern nur unstrukturiertes Rauschen in den Variablen. Wobei neuronale Netze nicht nur mit Gewichtungsfaktoren, sondern auch noch mit Schwellenwerten arbeiten und man manchen gar gestattet, bestehende Verbindungen zwischen einzelnen Neuronen zu kappen und neue zu knüpfen. Dadurch wird ihre Arbeitsweise noch undurchschaubarer. Das Innenleben eines neuronalen Netzwerks zeigt nicht an, was genau es leistet. Macht es einen Fehler, kann dieser nicht einfach auf einen Bug in der Programmierung zurückgeführt werden, sondern höchstens auf unzureichendes Training. Es gibt auch keine Stellschrauben in der Software, an denen man drehen könnte, um die Trefferquote zu erhöhen. Mehr Übung ist die einzige Option. Welche spezifischen Eigenschaften die für eine weitere Verbesserung geeigneten Trainingsdaten aufweisen müssen, ist ebenfalls nicht feststellbar. Ihre Erbauer vermögen also sehr genau zu beschreiben, was neuronale Netze eigentlich machen, aber nicht, wie sie zu einem bestimmten Ergebnis gelangen. Auf jeden Fall „denken“ sie nicht wie Menschen.
Tatsächlich bestimmen Computer, ob es nun um die Abstände von Datenpunkten zu Ausgleichskurven oder um die Kostenfunktion bei der Bildanalyse geht, unter Anwendung geeigneter mathematischer Methoden lediglich die Maxima oder Minima von Funktionen. Jedes Problem, das sich direkt oder indirekt in die Suche nach solchen Extremwerten überführen lässt, was unter anderem nahezu alle Aufgaben in klassischen Intelligenztests einschließt, vermögen Rechner zu bearbeiten. Alle anderen nicht. Künstliche Intelligenzen unterscheiden sich von herkömmlichen Algorithmen in der Fähigkeit, durch trickreich umgesetzte Verfahren sogar die Extremwerte äußerst komplexer Funktionen finden zu können. Sie sind eben deswegen „intelligent“, weil sie rein formal einen hohen Intelligenzquotienten erreichen könnten. Aber sie sind in keiner Hinsicht klug. Sie verfügen nicht über ein Weltmodell zur Einordnung ihrer Tätigkeit. Sie „wissen“ tatsächlich nichts über die Aufgabe, die man sie bearbeiten lässt und haben in dieser Hinsicht kein höheres intellektuelles Niveau als ein simpler Taschenrechner.
Neuronale Netze, die Automobile autonom bewegen, arbeiten mit Daten unterschiedlicher Sensoren. In dem so erhaltenen Umgebungsbild identifizieren sie potentielle Hindernisse mit genau der Vorgehensweise, die andere Künstliche Intelligenzen bei Katzenfotos einsetzen. Daraus ermitteln sie kollisionsvermeidende Steuerungsentscheidungen, die auch die Option beinhalten, einfach anzuhalten. Sie lernen dies in Simulationen und von menschlichen Fahrern, deren Verhalten sie bei realen Fahrten beobachten. Von der dazu eingesetzten Methodik abzuweichen, ist ihnen aber prinzipiell nicht möglich. Jedes ihrer Resultate ist als Ertrag einer Unsumme korrekt durchgeführter Kalkulationen eindeutig und nicht hinterfragbar. Die Mathematik bietet keinen Spielraum für Abwägungen, ohne die moralisches Handeln jedoch nicht auskommt. Ganz im Gegenteil wäre es überaus gefährlich, ein neuronales Netz dazu zu zwingen, Rechenergebnisse unter ethischen, also naturgemäß unscharfen Kriterien zusätzlich zu bewerten. Denn das würde erfordern, ihre durch langwieriges Training aufgebaute innere Struktur in beliebiger, unvorhersehbarer Weise zu verändern und damit nicht nur in kritischen, sondern in allen Situationen Fehler induzieren. Computer können eben nur „wenn/dann“. Aber nicht „sowohl/als auch“ oder „vielleicht/vielleicht auch nicht“.
Falls also tatsächlich einmal der überaus unwahrscheinliche Fall eintritt, in dem ein autonomes Fahrzeug auf keiner verfügbaren Trajektorie eine Kollision vermeiden kann, entscheidet der Zufall über das Geschehen. Es wird fast immer eine Vollbremsung einleiten, ohne die ursprüngliche Fahrtrichtung zu verändern. Pech hat also wahrscheinlich, wer genau im Weg steht, ganz gleich, um wen es sich handelt. Das nicht zu akzeptieren bedeutet, autonome Autos grundsätzlich abzulehnen.